
Zotero(6):如何批量下载PDF
本文假设你已经详细阅读过前面五篇,对Zotero有一定基础了。
Q1. 如何批量抓取PDF文档,快速了解研究者重点
在前面的文章中,你应该学会一个重要技巧了,就是通过【google学术】,根据作者名字或者论文名字,搜索出论文全文,然后批量保存到Zotero中。
但是,现实生活中,还常常存在另一类需求。就是作者很慷慨地提供了自己所有论文的PDF文档,列在个人网站上,以备同行引用。
因为作者自己提供的文档往往清晰度更高、比【Google学术】中根据作者名字搜出来的更齐全一些。怎么批量下载,然后导入到Zotero中?让我们来举个例子。
APA今年的奖评刚出来了。每年这些奖项里面,【早期职业生涯贡献奖】 与 【杰出贡献奖】 参考价值不错,一个代表心理学未来,获奖者:http://t.cn/8kxCp3n 一个代表心理学过去,获奖者:http://t.cn/8kxCp3E
其中,Linda B. Smith很猛,近两年双丰收。才拿2013年侧重认知科学基础卓越贡献奖的David E. Rumelhart奖(现在火爆的深度学习大牛Hinton是第一个拿这个奖的),今年又拿 【杰出贡献奖】 。她的个人主页:http://t.cn/8kxphwG
我们就以她的论文为例。
步骤如下:
1、安装一个chrome的批量下载插件:
Chrome Web Store - DownloadAll
2、访问Linda B. Smith提供出版物的网页,她恰巧在自己的个人网站上,提供了PDF全文列表,网址如下:
Cognitive Development Lab - Indiana University. Bloomington
点击该插件,如下图所示:
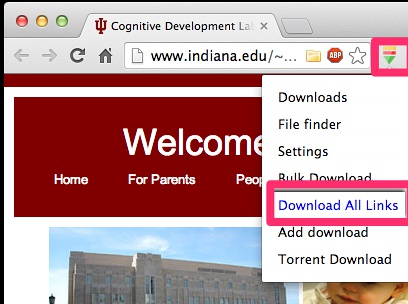
选择后缀为pdf,开始下载。如下图所示:
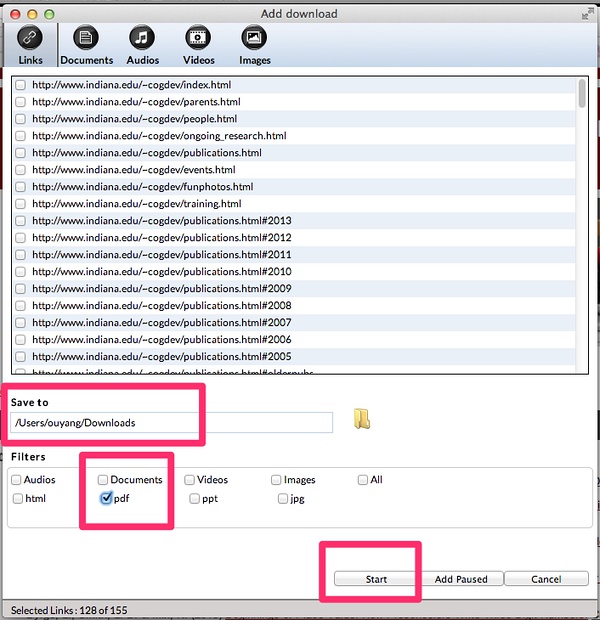
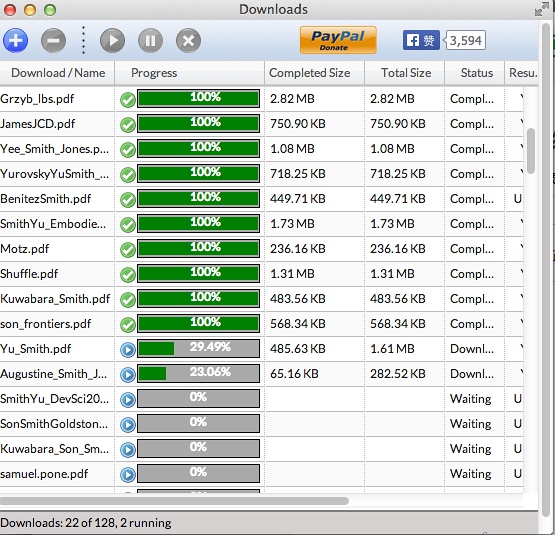
牛人发的论文就是多,一百多篇,咱们可以去喝杯咖啡,让它慢慢下载,如下图所示:
3、打开Zotero,新建一个目录,用于导入这些pdf,比如,我们建个目录,叫做:Linda B. Smith。
4、然后将下载的pdf文件,全部拖入到Linda B. Smith这个目录即可。如果你实在不知道怎么拖,就这么来,找到:【链接文件副本。。。】,然后按住shift键,选中所有下载的pdf文件。如下图所示:
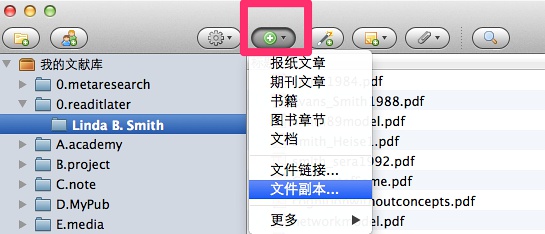
如果PDF文件太多,电脑内存较少,请注意别死机,可以考虑分批链接。
5、接下来,我们根据下载的PDF,批量生成文献信息,如下图所示,选中所有PDF文件,右键:
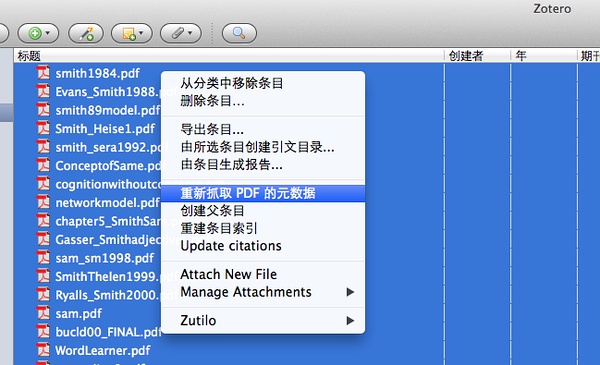
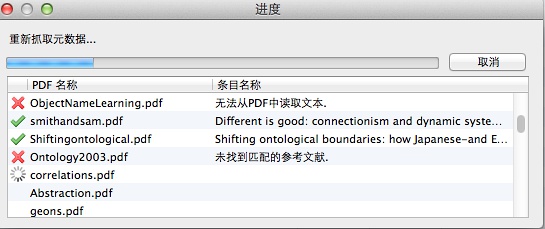
有些没找到文献信息的PDF,要么是年代过早,要么是版本保护问题,咱们先不管它。也请特别注意,一次别更新太多文献信息,【Google学术】目前有同一时间请求数量限制,50篇以内最好,超过后请稍候片刻。
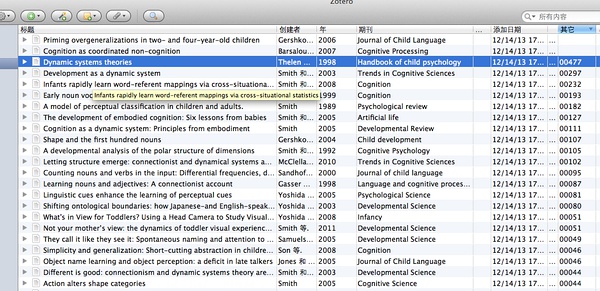
6、最后,看一下所有论文的【google学术引用次数】,按照【其它】字段排序。这样,我们就可以知道Linda B. Smith的核心论文是哪几篇了。
Q2. 如何建立自己的个性化知识库
今天,受我鼓吹,开始用Zotero的几位朋友,都在问我同一个问题:为什么不能保存国内某某网站、某某网站呢?
答:这是设计哲学的不同,它只默认抓取高质量信息,如google学术、science、经济学人、华尔街日报这些。 国内那些信息质量差的网站,不看也罢。
这是Zotero已支持的信息来源:http://t.cn/zTqrKc3
你可以自定义更多信息来源,或拍个网页快照来保存。如下图所示:
自定义信息类型与网页快照的区别是,网页快照不区分网页来源,也不进行个性化处理。无论来自什么网站,都统一是拍个快照。自定义信息类型,则可以进行更多精细加工处理。比如,将Zotero知识库列出什么菜谱、TED视频、问答。未来,你可以基于这个自定义信息类型,去进行更多的操作。你可以将它理解为一种对网上半结构化信息进行处理的手段。
在Zotero中,这个自定义信息类型,一般叫做:translators。有以下四种:
- Web translators:比如,抓取豆瓣图书,将其数据类型整理为book。这是一位开发者写好的: zotero/translators
- Import translators
- Export translators
- Search translators
第一种是最常用的。我们可以借助于Web translators,定义自己的TED视频库、菜谱库。。。只要你想得到,都可以处理。第一次定义成功后,未来,你再次访问时,直接网页收藏即可。
那么,如何自定义信息库呢?自定义Zotero抓取信息类型非常容易,无需太多编程知识,只需对github与js有点基础就可以了。 Zotero也提供了一个插件,参见该插件:http://t.cn/8k6CVsb 与该文档:[dev:translators [Zotero Documentation](http://www.zotero.org/support/dev/translators)
小结
本文介绍了两个Zotero实用技巧。一个是当研究者提供了所有出版物时,如何批量下载,以及根据批量下载后的PDF生成文献引用信息,继而根据【google学术引用次数】找出她最重要的论文;一个是,如何保存任意网页,并根据自己个性化需求,开发自定义的translators,从而打造一个个性化的知识库。